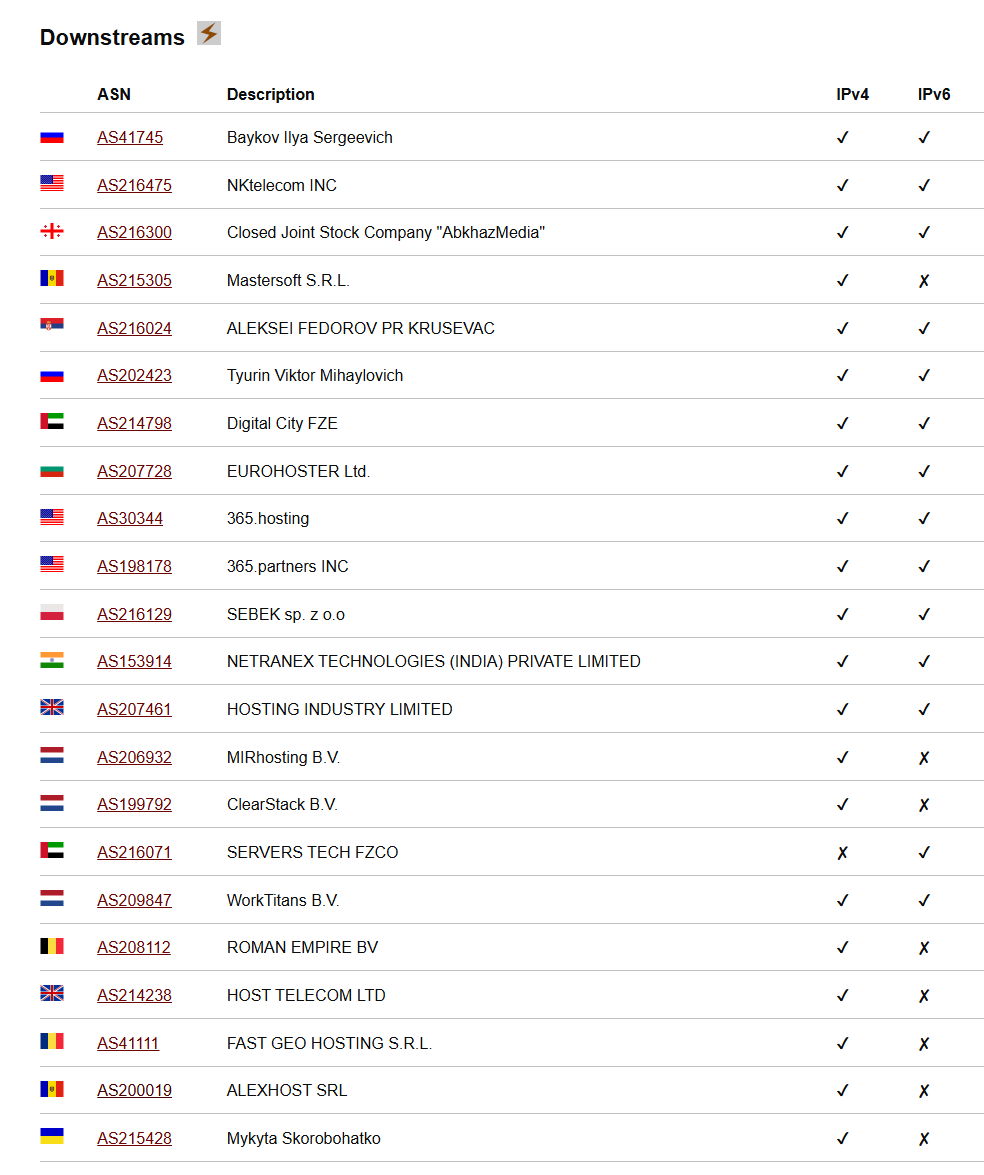
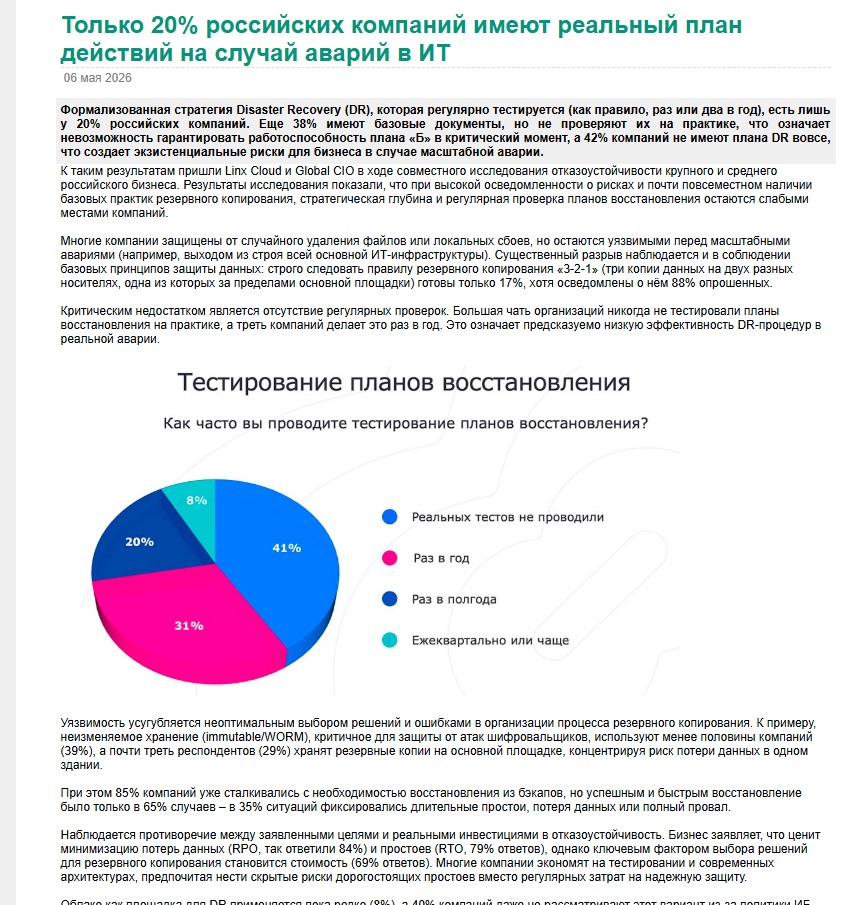
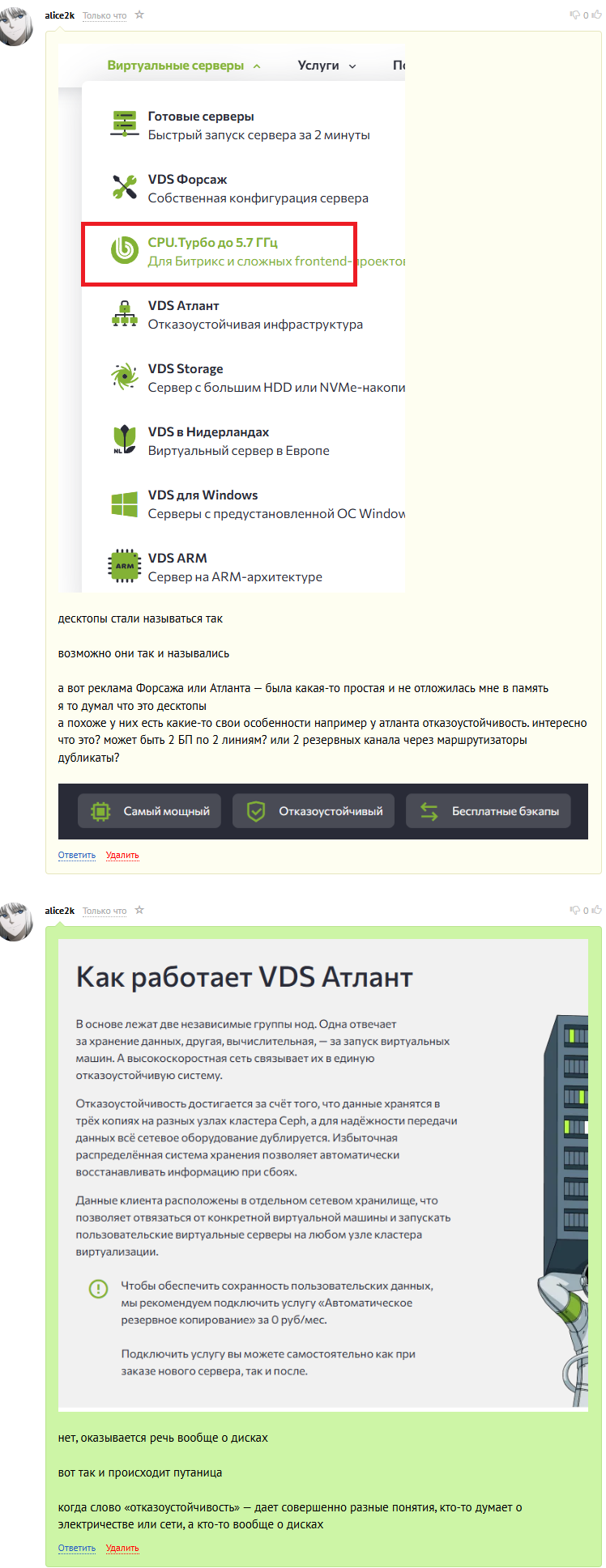
итого как мы понимаем - модель "присосаться" с дачей или самостроем - только лишь чтобы сделать связность и цену, но не отказоустойчивость
ранее в 2024 году я писал статьи
что проще всего построить самопал
и просто присосаться в готовую сетевую инфру
что это дало?
это дало бы связность сети и хорошую сеть на которую не жалуются
и дало бы дешевый интернет
но не дало бы отказоустойчивости
поэтому все равно нужно прокладывать самому рыть траншеи
если ты собираешься делать отказоустойчивый надежный сервис
а для дедиков нужен надежный сервис, дедик это платформа для качественных проектов
вдс-ка всякая да, она может полежать и похуй, никто там ценного ничего не держит
что проще всего построить самопал
и просто присосаться в готовую сетевую инфру
что это дало?
это дало бы связность сети и хорошую сеть на которую не жалуются
и дало бы дешевый интернет
но не дало бы отказоустойчивости
поэтому все равно нужно прокладывать самому рыть траншеи
если ты собираешься делать отказоустойчивый надежный сервис
а для дедиков нужен надежный сервис, дедик это платформа для качественных проектов
вдс-ка всякая да, она может полежать и похуй, никто там ценного ничего не держит